My brother nerd sniped me the other day. He wanted to see if he could extract the images out of an old game by Ambrosia Software called “Slithereens”. It was released on 1998-12-15 for Mac OS 9. That sounds easy enough…

Digging though resource forks
Old Mac OS had the ability to have a 2nd plane of data on a file called a “resource fork”. Rather than being just arbitrary binary blobs, they had some structure to them. Back in the day there was tool called “ResEdit” from Apple that let you poke around Resource Forks. Today there are open source clones out there. I grabbed “ResForge” to look around with a nice GUI. I could have also used /usr/bin/derez which still ships with the developer tools even on the latest macOS 13.
Here’s the list of resources in the Slithereen Sprites resource files:
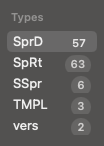
There’s just a handful of types. Poking around it looks like the SpRt resources contain metadata about the animations and the SpRd resources are just raw data, probably bitmaps.
Here’s a SpRt resource for the “Player 1 Head” sprite:
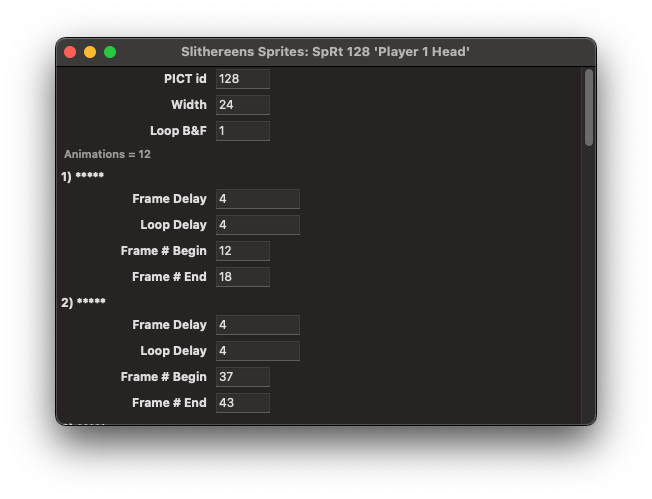
That’s got a bunch of stuff, but really the only super interesting piece of data is the width: 24 pixels.
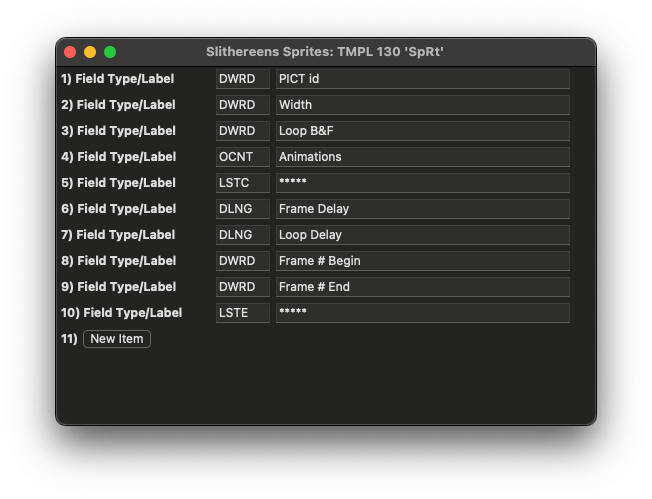
As an aside, how did they get their custom animation data to show up parsed like that? That’s actually a cool feature of ResEdit—you can defined TMPL resources in your file and ResEdit will use them to decode and print your data nicely, allowing you to edit stuff right right from ResEdit and without any custom tools. Many programs would ship with their TMPLs and so you could open the application with ResEdit and poke around their data. It’s sort of the equivalent of finding a .json file in someones app nowadays. Here’s the TMPL for the SpRt resource:
I didn’t want to start with the “Player 1 Head” sprite though. I wanted something more recognizable that would help when looking for patterns. A 24×24 square with a semi-circular snake head in the middle seemed to hard. I checked out the screenshot and noticed the “Level” text in the bottom right corner, which seemed promising:

Distinctive shape, wider than it is tall. It looked like it was in a sprite called “Level”, so I checked out the SpRt resource:
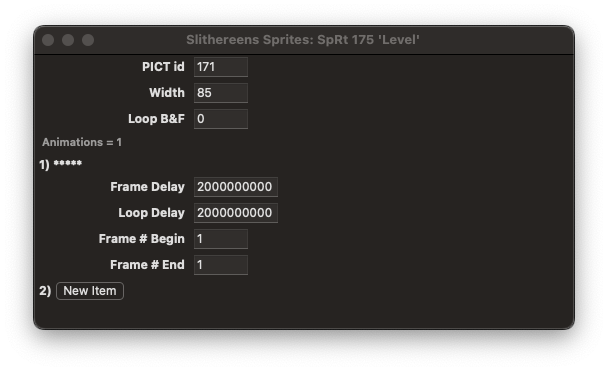
It’s just a single animation frame, which seems like a good idea to start with—less complications up front.
Width 85. I can remember that number… But no Height for some reason. I zoomed up the screenshot and manually counted the pixels in the Level sprite. It looks like it is 22 pixels high.
Now lets look at the data (in the SpRd resource):
I glance at this a little, but my eyes glaze over. It’s probably just bitmap data, after all.
What I don’t know, though, is the layout of the bitmap data. It probably goes top left to bottom right (as was the style of the time), but that’s not a given. What if it’s rotated or something weird? And how many Bits per Pixel (“BPP”) is it? 8 bit seems reasonable for that timeframe, but it could also be 4—it doesn’t look like the sprites each have a ton of color.
So I’m thinking I want a little data structure that I can read arbitrary bits from so that I can try rendering the bitmap with different BPPs. I decided to write it in Ruby and came up with this little class:
class Bits
def initialize(bytes=[])
@bytes = bytes
end
def get(offset, length)
v=0
while length > 0
start = offset / 8
bit = offset % 8
bs = bit
be = [8, bs+length].min
bits = be - bit
v = v<<bits | @bytes[start] >> (8 - be) & 0xff >> (8 - bits)
offset+=bits
length-=bits
end
v
end
end
I also need the sprite data. I’ve saved the RsRd file out from ResForge and I can poke an prod it from the command line now. I read the man page for xxd and discovered the -i option which sounds perfect:
-i | -include: Output in C include file style. A complete static array definition is written (named after the input file), unless xxd reads from stdin.
Neat. Now I can just do:
$ xxd -i Level.sprd > level.rb
And then convert the C-ism to Ruby-ism in Emacs.
I also write a little dump routine to dump the bitmap in rows and columns:
def dump(data, width, height, bpp, start=0, stride=width)
(0..height).each {|y|
(0..width).each {|x|
pix=data.get(start + y * stride * bpp + x * bpp, bpp)
printf("%*b ", bpp, pix)
}
puts ""
}
end
I don’t know if I’ll need stride or start, but it’s easy enough to add them now—maybe they’ll turn out to be important later.
dump(head, 12, 12, 4)
produces
0 0 0 0 0 0 0 0 0 0 1 1000 0
0 0 1 1000 0 0 0 0 0 10 101 0 0
0 0 0 0 0 1 1 11 0 0 1 1000 0
0 1 10 1011 0 1 0 0 0 0 0 0 0
0 1 0 0 0 0 0 0 0 1 0 0 0
0 0 0 0 0 1 0 0 0 0 0 0 0
0 1 0 0 0 0 1 100 0 11 0 0 0
0 0 0 1010 0 10 0 0 0 0 0 1001 1111
1111 1111 1111 1111 1111 1111 1111 1111 1111 1111 1111 1111 1111
1111 1111 1111 1111 1111 1111 0 0 0 0 0 0 0
0 1 0 0 0 0 1 100 0 11 0 0 0
0 0 0 1000 0 10 0 0 0 0 0 1100 1111
1111 1111 1111 1111 1010 1100 1111 110 1000 1 1010 111 1010
It doesn’t really look like anything. If you kind of squint the different patterns look like different greyscale blobs. Kinda. I play around with some numbers and run it a bunch of times but I can’t make the it look like anything except gibberish.
I end up tweaking the code to output either X or Space instead of the numbers (full program here):
dump(level, 85, 22, 8) {|pix| pix==0 ? " " : "X"}
produces
X X XX X XX X XX XX XXXXXXXXXX X XX XXXXXX X XX XX XXXXXXXXXXX
XXXX XX XXXXXXXXXX XX XX XXXXXXXXXXXXXX X XX XXXXXXXXXXX X XX XX XXXXXXXX
XXXXXXX X XX XXXXXXXXXXX X XX XX XXXXXXXXXXXXXX X XX XXXXXXXXXXX X XX X
XX XXXXXXXXXXXX X XX XXXXXXXXXXX X XX XX XXXXXXXXXX XX XXXXXX X XX XXXXXX
XXXXX X XX XXXXXXX X XX XXXXXXX X XX XXXXXXXXXX X XX XX XXXXXXXXXX XX
XXXXXXXXXX X XX XXXXXXXXXXXXXXXXXXXXXX XX XXXXXXXXXXX X XX XXXXXXXXXX XX
XX XXXXXXXXXX XX XXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXX X XX XXXXXXXXX
XX XX XX XXXXXXXXXX XX XXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXX XX XX
XXXXXXXXX XX XX XXXXXXXXXX XX XXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXX
X XX XXXXXXXXXX XX XX XXXXXXXXXX XX XXXXXXXXXXXXXXXXXX XX XXXXXXXXXXXXXXXX
XXXXXXXXXXXXXXXXXXX X XX XXXXXXXXXX XX XX XXXXXXXXXX XX XXXXXXXXXXXXXXXXXX X
XX XXXXXXXXXXXXXXX X XX XXXXXXXXXXXXXXXXXX X XX XXXXXXXXXX XX XX XXXXXXXXXX
X XX XXXXXXXXXXXXXXXXXXXXXX X XX XXXXXXXXXXXXXXX X XX XXXXXXXXXXXXXXXXXX X
XX XXXXXXXXXX XX XX XXXXXXXXXX XX XXXXXXXXXXXXXXXXXXXXXX X XX XXXXXXXXXXXX
XXX XX XXXXXXXXXXXXXXXXXX X XX XXXXXXXXXX XX XX XXXXXXXXXX XX XXXXXXXXXXXXX
XXXXXXXXXX XX XXXXXXXXXXXX X XX XXXXXXXXXXXXXXXXXX XX XXXXXXXXXX XX XX XXXXXX
XXXXX X XX XXXXXXXXXXXXXXXXXXXXXX X XX XXXXXXXXXXX X XX XXXXXXXXXXXXXXXXXX
XX XXXXXXXXXX X XX XX XXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXX X XX XXXXXXXXXX
X XX XXXXXXXXXXXXXXXXXX XX XXXXXXXXXXXXXX XX XX XXXXXXXXXXXXXXXXXXXX X XX X
XXXXXXXXXXXXXXX X XX XXXXXXXXXX XX XXXXXXXXXXXXXXXX X XX XXXXXXXXXXXXXX XX XX
X XXXXXXXXXXXXXXXXXXX X XX XXXXXXXXXXXXXX X XX XXXXXXXX X XX XXXXXXXXXXXXXXX
X X XX XXXXXXXXXXXXXX XX XX XXXXXXXXXXXXXXXXXXX X XX XXXXXXXXXXXX X XX XXXX
XXX X XX XXXXXXXXXXXXXX XX XXXXXXXXXXXX X XX XX XXXXXXXXXXXXXXXXXX X XX X
That doesn’t look like anything. I tweak more numbers but each time I have to edit the file then run it to get results. It feels slow. I need my turn-around time faster! I kinda want a little UI and maybe have it respond to keystrokes. I start to think a web app could be nice…
So I rewrite those same little code chunks in javascript. Now that I have a browser I can drop <input> tags down, grab a canvas and draw actual rectangles of different colors instead of printing Xs. I get it working and it’s still kinda slow, deleting those numbers and incrementing them—sounds dumb but requires thought and I want to focus on looking for patterns not remembering how to type numbers quickly.
The easy answer is to make “PgUp” and “PgDown” increment and decrement the number (and “Home” and “End” to increment and decrement by 10). This finally feels good. So I sit down and play:
Can you get it to display something resembling the words “Level”? I sure couldn’t. I started thinking this probably wasn’t a straight bitmap.
Take 2
My next guess was some sort of run length encoding (“RLE”). This can be used to compress the data (very simply). My brother had another idea though—he thought they might be PICT files. I wasn’t sure—why wouldn’t they put them in PICT resources then? But I don’t remember how PICTs work so I couldn’t rule it out.
Turns out the Inside Macintosh series of books described the PICT format. I still have mine on the shelf in the other room, but it’s much easier to just search google. Luckily, Apple still has them on their web site.
Inside Mac Appendix about Quickdraw had this example picture data:
data 'PICT' (129) {
$"0078" /* picture size; don't use this value for picture size */
$"0002 0002 006E 00AA" /* bounding rectangle of picture */
$"0011" /* VersionOp opcode; always $0011 for version 2 */
$"02FF" /* Version opcode; always $02FF for version 2 */
$"0C00" /* HeaderOp opcode; always $0C00 for version 2 */
/* next 24 bytes contain header information */
$"FFFF FFFF" /* version; always -1 (long) for version 2 */
$"0002 0000 0002 0000 00AA 0000 006E 0000" /* fixed-point bounding
rectangle for picture */
$"0000 0000" /* reserved */
$"001E" /* DefHilite opcode to use default hilite color */
$"0001" /* Clip opcode to define clipping region for picture */
$"000A" /* region size */
$"0002 0002 006E 00AA" /* bounding rectangle for clipping region */
$"000A" /* FillPat opcode; fill pattern specifed in next 8 bytes */
$"77DD 77DD 77DD 77DD" /* fill pattern */
$"0034" /* fillRect opcode; rectangle specified in next 8 bytes */
$"0002 0002 006E 00AA" /* rectangle to fill */
$"000A" /* FillPat opcode; fill pattern specified in next 8 bytes */
$"8822 8822 8822 8822" /* fill pattern */
$"005C" /* fillSameOval opcode */
$"0008" /* PnMode opcode */
$ "0008" /* pen mode data */
$"0071" /* paintPoly opcode */
$"001A" /* size of polygon */
$"0002 0002 006E 00AA" /* bounding rectangle for polygon */
$"006E 0002 0002 0054 006E 00AA 006E 0002" /* polygon points */
$"00FF" /* OpEndPic opcode; end of picture */
}
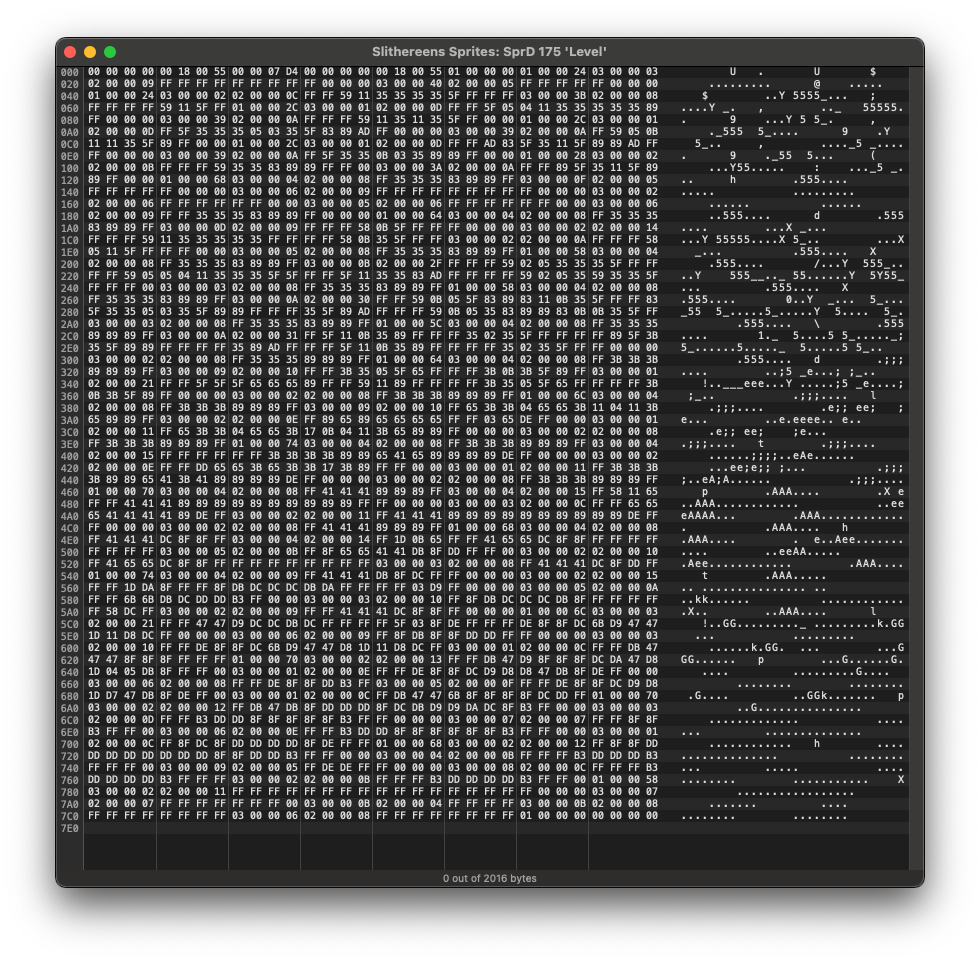
Lets hex dump our SpRd data and see if it matches up. All these dumps are big endian, as the all the old 680×0 and PowerPC Macs were big endian machines (technically PowerPC CPUs could run in either little endian or big endian mode, but MacOS Classic always run in big-endian mode):
00000000: 0000 0000 0018 0055 0000 07d4 0000 0000 .......U........
00000010: 0018 0055 0100 0000 [01]00 0024 [03]00 0003 ...U.......$.... => Suspicously aligned 1 #first-byte-1, Suspicously aligned 3 #first-byte-3
00000020: [02]00 0009 ffff ffff ffff ffff ff00 0000 ................ => Suspiciously aligned 2 #first-byte-2
00000030: [03]00 0040 [02]00 0005 ffff ffff ff00 0000 ...@............ => Suspicously aligned 3 #first-byte-3, Suspiciously aligned 2 #first-byte-2
00000040: [01]00 0024 [03]00 0002 [02]00 000c ffff 5911 ...$..........Y. => Suspicously aligned 1 #first-byte-1, Suspicously aligned 3 #first-byte-3, Suspiciously aligned 2 #first-byte-2
00000050: 3535 3535 5fff ffff [03]00 003b [02]00 0008 5555_......;.... => Suspicously aligned 3 #first-byte-3, Suspiciously aligned 2 #first-byte-2
00000060: ffff ffff 5911 5fff [01]00 002c [03]00 0001 ....Y._....,.... => Suspicously aligned 1 #first-byte-1, Suspicously aligned 3 #first-byte-3
00000070: [02]00 000d ffff 5f05 0411 3535 3535 3589 ......_...55555. => Suspiciously aligned 2 #first-byte-2
00000080: ff00 0000 [03]00 0039 [02]00 000a ffff ff59 .......9.......Y => Suspicously aligned 3 #first-byte-3, Suspiciously aligned 2 #first-byte-2
That doesn’t match up, so I decide to rule out PICTs.
But I happen to notice a lot of 03, 02, and 01 in the high byte of u32 aligned words (annotate).
I try dumping the data with xxd -c 4 -g 4 (group by 4, 4 bytes per line):
00000000: 00000000 ....
00000004: 00180055 ...U
00000008: 000007d4 ....
0000000c: 00000000 ....
00000010: 00180055 ...U
00000014: [01]000000 .... => First Byte == 1
00000018: [01]000024 ...$ => First Byte == 1
0000001c: [03]000003 .... => First Byte == 3
00000020: [02]000009 .... => First Byte == 2
00000024: ffffffff ....
00000028: ffffffff ....
0000002c: ff000000 ....
00000030: [03]000040 ...@ => First Byte == 3
00000034: [02]000005 .... => First Byte == 2
00000038: ffffffff ....
0000003c: ff000000 ....
00000040: [01]000024 ...$ => First Byte == 1
00000044: [03]000002 .... => First Byte == 3
00000048: [02]00000c .... => First Byte == 2
0000004c: ffff5911 ..Y.
Full listing here
That looks more promising. In fact the entire thing seems to be u32 aligned and the first bytes seem mostly similar.
The 01, 02, 03 words don’t start right away, which means there’s probably a file header up front.
I remember that the SpRt resource for the “Level” sprite says the width is “85”—that’s is 0x55 in hex. I see that in the first few words a couple times:
00000000: [00000000] .... => Unknown zeros #zeros
00000004: [0018][0055] ...U => Height #height,Width
00000008: [000007d4] .... => Unknown length #length
[0000000c]: [00000000] .... => Offset the length is based from #offset, Unknown zeros #zeros
00000010: [0018][0055] ...U => Height (Again!) #height,Width (Again!)
0x18 is 24 decimal, which is what we think the height of the sprites is (annotate). I got 22 by pixel counting, but 24 is close enough. There are some zeros that I don’t understand yet (annotate), and a 0x7d4 (annotate). That looks big enough to maybe be a length. I ls -l the file which says it’s 2016 bytes long, which is 0x7e0. That’s extremely close to 0x7d4, so it’s probably related. In fact, if we subtract them to see just how close they are then we get 12, or 0xc. Aha! That corresponds to the file offset just after the length (annotate), which means that is the length of the rest of the file.
So far the theory is that this is a header with some zeros that are unknown, a height and width, the length of the file (measure from just after reading that u32), and then the zeros and width and height again for some reason. Let’s not worry about that for now, let’s look at the rest.
After staring at the data for a while I notice that whenever there are words that don’t start with 01, 02, or 03, that they always come after a 02. If we take some random sections of the file and look at them maybe we can see a pattern:
00000020: [02][000009] .... => Command 2, Length = 9 #data_l
00000024: [ffffffff] .... => Data #data_b
00000028: [ffffffff] .... => Data #data_b
0000002c: [ff][000000] .... => Data #data_b, Padding for alignment #align
000000e8: [02][00000a] .... => Command 2, Length = 0xa (10) #data_l
000000ec: [ff5f3535] ._55 => Data #data_b
000000f0: [0b033589] ..5. => Data #data_b
000000f4: [89ff][0000] .... => Data #data_b, Padding for alignment #align
000003f0: [02][000008] .... => Command 2, Length = 8 #data_l
000003f4: [ff3b3b3b] .;;; => Data #data_b
000003f8: [898989ff] .... => Data #data_b
0000055c: [02][000015] .... => Command 2, Length = 0x15 (21) #data_l
00000560: [ffff1dda] .... => Data #data_b
00000564: [8fffff8f] .... => Data #data_b
00000568: [dbdcdcdc] .... => Data #data_b
0000056c: [dbdaffff] .... => Data #data_b
00000570: [ffff03d9] .... => Data #data_b
00000574: [ff][000000] .... => Data #data_b, Padding for alignment #align
The longer the trailing data is (until the next 01 or 03), the larger that lower byte in the 02 u32. In fact, I count them and it looks like that is a precise byte count (annotate). When it doesn’t align to 32 bits it’s filled with zeros (annotate)! Skimming through the file I don’t see anything that counters this. So lets code it up and see if it’s really true. I decide to call these u32s that start with 01, 02 and 03 (and the 00 I notice at the very end) “commands”, though I don’t know exactly what they are yet.
I need to add a couple helper functions to the Bits class (which got converted to Javascript) to read bytes in a more file like way:
seek(offset) { this.cursor = offset }
tell() { return this.cursor }
read(bytes) {
let b = this.bytes.slice(this.cursor, this.cursor+bytes)
this.cursor += bytes
return b;
}
readn(n) { return this.read(n).reduce((acc, b) => acc << 8 | b, 0) }
read8() { return this.readn(1) }
read16() { return this.readn(2) }
read24() { return this.readn(3) }
read32() { return this.readn(4) }
and an ambitiously titled unpack() (ambitious because it does nothing of the sort) to test the theory:
function unpack(data) {
console.log("header")
console.log(` x,y? ${data.read16()},${data.read16()}`)
console.log(` height ${data.read16()}`)
console.log(` width ${data.read16()}`)
let length = data.read32()
console.log(` length ${dec_and_hex(length)} ` +
`(end:${dec_and_hex(data.tell() + length)})`)
console.log(` again x,y? ${data.read16()},${data.read16()}`)
console.log(` again height ${data.read16()}`)
console.log(` again width ${data.read16()}`)
let c = 0
while (true) {
let command = data.read(4)
console.log(`command[${c} (${hex(data.tell())})] ${command[0]} ` +
`[${hex(...command)}]`)
if (command[0] == 0) break;
if (command[0] == 2) {
let chunk = data.read(command[3]);
// this is wrong if len == 0: -1%4 => -1 in js. yuck.
let align = data.read((3 - ((command[3]-1) % 4)));
console.log(` chunk ${hex(...chunk)} | ${hex(...align)}`);
}
c += 1
}
console.log(`end @ ${hex(data.tell())}`)
}
The output looks like:
header
x,y? 0,0
height 24
width 85
length 2004 [7d4] (end:2016 [7e0])
again x,y? 0,0
again height 24
again width 85
command[0 (18)] 1 [01 00 00 00]
command[1 (1c)] 1 [01 00 00 24]
command[2 (20)] 3 [03 00 00 03]
command[3 (24)] 2 [02 00 00 09]
chunk ff ff ff ff ff ff ff ff ff | 00 00 00
command[4 (34)] 3 [03 00 00 40]
command[5 (38)] 2 [02 00 00 05]
chunk ff ff ff ff ff | 00 00 00
command[6 (44)] 1 [01 00 00 24]
command[7 (48)] 3 [03 00 00 02]
command[8 (4c)] 2 [02 00 00 0c]
chunk ff ff 59 11 35 35 35 35 5f ff ff ff |
[... snip ...]
command[189 (7bc)] 3 [03 00 00 0b]
command[190 (7c0)] 2 [02 00 00 08]
chunk ff ff ff ff ff ff ff ff |
command[191 (7cc)] 3 [03 00 00 06]
command[192 (7d0)] 2 [02 00 00 08]
chunk ff ff ff ff ff ff ff ff |
command[193 (7dc)] 1 [01 00 00 00]
command[194 (7e0)] 0 [00 00 00 00]
end @ 7e0
Hey, that theory looks correct. It even ends on a nice 00 command as some kind of null terminator.
But what are 01 and 03 for??
000000e4: [03][000039] ...9 => Command 3, Repeat count #repeat_l
000000e8: [02][00000a] .... => Command 2, Data count #+data_l
000000ec: [ff5f3535] ._55 => Data #+data_b
000000f0: [0b033589] ..5. => Data #+data_b
000000f4: [89ff][0000] .... => Data #+data_b, Padding for alignment #+align
000000f8: [01][000028] ...( => Command 1, Skip count? #skip_l
000000fc: [03][000002] .... => Command 3, Repeat count? #repeat_l
00000100: [02][00000b] .... => Command 2, Data count #+data_l
00000104: [ffffff59] ...Y => Data #+data_b
00000108: [35358389] 55.. => Data #+data_b
0000010c: [89ffff][00] .... => Data #+data_b, Padding for alignment #+align
00000110: [03][00003a] ...: => Command 3, Repeat count? #repeat_l
00000114: [02][00000a] .... => Command 2, Data count #+data_l
00000118: [ffff895f] ..._ => Data #+data_b
0000011c: [35115f89] 5._. => Data #+data_b
00000120: [89ff][0000] .... => Data #+data_b, Padding for alignment #+align
00000124: [01][000068] ...h => Command 1, Skip count? #skip_l
00000128: [03][000004] .... => Command 3, Repeat count? #repeat_l
0000012c: [02][000008] .... => Command 2, Data count #+data_l
00000130: [ff353535] .555 => Data #+data_b
00000134: [838989ff] .... => Data #+data_b
00000138: [03][00000f] .... => Command 3, Repeat count? #repeat_l
0000013c: [02][000005] .... => Command 2, Data count #+data_l
Since I suspect it’s some sort of RLE, I start thinking along those lines. With a run length encoding you usually have some sort of “repeat” code. I notice that the 03 command always comes before a 02 command. So I make a guess. I think maybe 03 is a “repeat” command (annotate). But then what is 01? I think that may be a “skip” command (annotate)—it’s kind of sporadic but it always comes before the repeat. And the 02 command must be verbatim data (annotate). Well… Just theorizing gets us nowhere, lets try it out!
First I need another couple functions in the Bits class, one for writing and a quickie hex dump function to check my work…
write(data) {
this.bytes.splice(this.cursor, data.length, ...data)
this.cursor += data.length
}
dump() {
return this.bytes.reduce((acc,b,i) => { let ch = Math.floor(i/16);
acc[ch] = [...(acc[ch]??[]), b];
return acc }, [])
.map(row => row.map(b => hex(b)).join(", ") + "\n")
.join('');
}
The write() function replaces the bytes at the cursor with the data passed in (it does not insert).
Now I modify up the unpack() function (which is finally living up to its name!):
function unpack(data) {
let out = new Bits()
console.log("header")
console.log(` x,y? ${data.read16()},${data.read16()}`)
console.log(` height ${data.read16()}`)
console.log(` width ${data.read16()}`)
let length = data.read32()
console.log(` length ${dec_and_hex(length)} ` +
`(end:${dec_and_hex(data.tell() + length)})`)
console.log(` again x,y? ${data.read16()},${data.read16()}`)
console.log(` again height ${data.read16()}`)
console.log(` again width ${data.read16()}`)
let c = 0
let repeat;
while (true) {
let command = data.read(4)
console.log(`command[${c} (${hex(data.tell())})] ${command[0]} ` +
`[${hex(...command)}]`)
if (command[0] == 0) break;
if (command[0] == 1) // skip forward (write zeros)?
out.write(Array(command[3]).fill(0))
else if (command[0] == 3) // repeat the next command n times?
repeat = command[3]
else if (command[0] == 2) {
let chunk = data.read(command[3]);
// this is wrong if len == 0: -1%4 => -1 in js. yuck.
let align = data.read((3 - ((command[3]-1) % 4)));
console.log(` chunk ${hex(...chunk)} | ${hex(...align)}`);
out.write(Array(repeat).fill(chunk).flat())
}
c += 1
}
console.log(`end @ ${hex(data.tell())}`)
console.log(out.dump())
return out;
}
I get some data out! Lets graph it to see if it works:
Play around, can you find the image?
[spoiler] I couldn’t either. 🙁
Hmm. I start looking at the output, and it just doesn’t make any sense. First off it’s way too big—85×24 at 8 bits per pixel is 2040 bytes and the output is 9627 bytes long. And that’s not off by a good multiple either. Second off, the repeat counts on some stuff is really high which seems wrong.
Back to the drawing board
I decide this is just wrong and stare at the “command list” again. My brother and I started screen sharing so we could have 2 heads working on the problem. I really wanted to figure out what the 01 commands are for. That first one with zeros is weird, and there’s another one like that at the end. So my initial “skip” thought doesn’t really make sense because why skip zero? What could its number mean? We search through the file and notice the number after the 01 command generally gets bigger as we go farther into the file. On a whim I go through and stick a newline before each 01 command. It ends up looking like this:
00000000: [00000000] .... => Unknown zeros #+zeros
00000004: [0018][0055] ...U => Height, Width
00000008: [000007d4] .... => File length #+length
[0000000c]: [00000000] .... => Offset the length is based from #+offset, Unknown zeros #+zeros
00000010: [0018][0055] ...U => Height (Again!) #+height, Width (Again!) #+width
00000014: [01][000000] .... => Command 1, Length (0 + 0x00000018) #command_1_l
[00000018]: [01][000024] ...$ => Offset the above length is based from #command_1_o, Command 1, Length (0x24 + 0x0000001c == 0x00000040) #command_1_l
[0000001c]: 03000003 .... => Offset the above length is based from #command_1_o
00000020: 02000009 ....
00000024: ffffffff ....
00000028: ffffffff ....
0000002c: ff000000 ....
00000030: 03000040 ...@
00000034: 02000005 ....
00000038: ffffffff ....
0000003c: ff000000 ....
00000040: [01][000024] ...$ => Command 1, Length (0x24 + 0x00000044 = 0x00000068) #command_1_l
[00000044]: 03000002 .... => Offset the above length is based from #command_1_o
00000048: 0200000c ....
0000004c: ffff5911 ..Y.
00000050: 35353535 5555
00000054: 5fffffff _...
00000058: 0300003b ...;
0000005c: 02000008 ....
00000060: ffffffff ....
00000064: 59115fff Y._.
[... snip ...]
0000077c: [01][000058] ...X => Command 1, Length (0x58 + 0x00000780 = 0x7d8) #command_1_l
[00000780]: 03000002 .... => Offset the above length is based from #command_1_o
00000784: 02000011 ....
00000788: ffffffff ....
0000078c: ffffffff ....
00000790: ffffffff ....
00000794: ffffffff ....
00000798: ff000000 ....
0000079c: 03000007 ....
000007a0: 02000007 ....
000007a4: ffffffff ....
000007a8: ffffff00 ....
000007ac: 0300000b ....
000007b0: 02000004 ....
000007b4: ffffffff ....
000007b8: 0300000b ....
000007bc: 02000008 ....
000007c0: ffffffff ....
000007c4: ffffffff ....
000007c8: 03000006 ....
000007cc: 02000008 ....
000007d0: ffffffff ....
000007d4: ffffffff ....
000007d8: [01][000000] .... => Command 1, Length (0 + 0x000007dc) #command_1_l
[000007dc]: 00000000 .... => Offset the above length is based from #command_1_o
Interestingly, not only do the numbers get bigger through the file, the distance between 01 commands gets bigger, too. Also I notice those numbers are very round, the lower nibble of every 01 command is 0, 4, 8, or c. That’s u32 aligned. It must be a length! Sure enough, That first non-zero chunk has a 0x24. If we add that to the next address (same as the length in the header) we get 0x24+0x1c => 0x40, which is exactly the address where the next 01 commands starts (annotate). Eureka! We spot check a few more and they all agree with this.
Still, what does 01 signify? It has a length like it’s wrapping something, but what concept is it wrapping? I decided to see how many there are in the file. There are 24 including the ones with 00 length. Hey! 24 is the height! These are lines! (annotate) And that makes some sense, too: earlier I said I pixel counted and got 22 pixels on the level font, but the file said it was 24 high. The reason for that discrepancy is 2 blank lines, and 00 length makes a lot of sense for a blank line.
So that seems like very strong evidence to me but we can’t decode without figuring out what the other commands do. I’m pretty sure I was right about the 02 command meaning “verbatim data”, but what is the 03? Well, let’s look at the first non-blank line again:
00000018: [01][000024] ...$ => Line Command, Line length (0x24 + 0x0000001c == 0x00000040) #+command_1_l
0000001c: [03][000003] .... => Command 3 #+skip, Skip count #skip_c
00000020: [02][000009] .... => Verbatim Data Command #+data, Verbatim Data Length #+data_l
00000024: [ffffffff] .... => Data #+data_b
00000028: [ffffffff] .... => Data #+data_b
0000002c: [ff][000000] .... => Data #+data_b, Padding #+align
00000030: [03][000040] ...@ => Command 3 #+skip, Skip count #skip_c
00000034: [02][000005] .... => Verbatim Data Command #+data, Verbatim Data Length #+data_l
00000038: [ffffffff] .... => Data #+data_b
0000003c: [ff][000000] .... => Data #+data_b, Padding #+align
I have a guess… I think it’s the skip (which I previously thought was command 01). (annotate) Before coding we can do a spot check to see if this seems correct: We can look at the commands in this line and see if they make sense.
That would be: skip 0x3, verbatim 0x9, skip 0x40, verbatim 0x5. In total that’s 0x51, which is 81 in decimal. That’s very close to the width of 85! It’s even kind of centered comparing against the first skip (3 vs 4). So that’s looking promising, let’s code it up!
function unpack(data) {
console.log("header")
console.log(` x,y? ${data.read16()},${data.read16()}`)
console.log(` height ${data.read16()}`)
console.log(` width ${data.read16()}`)
let length = data.read32()
console.log(` length ${dec_and_hex(length)} ` +
`(end:${dec_and_hex(data.tell() + length)})`)
console.log(` again x,y? ${data.read16()},${data.read16()}`)
let height = data.read16();
let width = data.read16();
console.log(` again height ${height}`)
console.log(` again width ${width}`)
let out = new Bits(Array(width * height).fill(0))
let c = 0
let repeat;
let line = -1
while (true) {
let command = data.read(4)
console.log(`command[${c} (${hex(data.tell())})] ${command[0]} [${hex(...command)}]`)
if (command[0] == 0) break;
else if (command[0] == 1) { // Line header
line += 1
let sol = line * width
out.seek(sol)
} else if (command[0] == 3) { // Skip forward (write zeros)?
out.write(Array(command[3]).fill(0))
} else if (command[0] == 2) {
let chunk = data.read(command[3])
// this is wrong if len == 0: -1%4 => -1 in js. yuck.
let align = data.read((3 - ((command[3]-1) % 4)));
out.write(chunk)
}
c += 1
}
return out;
}
And that produces…
Woohoo! Success!
“But what about the colors”, my brother asks. Oh. Well, that’s probably not too hard…
Color
I explain about color lookup tables (often called “cluts”) and we find one named “standard” in a resource file. He dumps it to binary and we take a look with xxd -c 8:
00000000: [0000 0000] [0000 00ff] ........ => First color index #zeros, Last color index #max_color
00000008: [0000] [ffff] [ffff] [ffff] ........ => Color index #index, Red #red, Green #green, Blue #blue
00000010: [0001] [ffff] [ffff] [cccc] ........ => Color index #index, Red #red, Green #green, Blue #blue
00000018: [0002] [ffff] [ffff] [9999] ........ => Color index #index, Red #red, Green #green, Blue #blue
00000020: [0003] [ffff] [ffff] [6666] ......ff => Color index #index, Red #red, Green #green, Blue #blue
00000028: [0004] [ffff] [ffff] [3333] ......33 => Color index #index, Red #red, Green #green, Blue #blue
00000030: [0005] [ffff] [ffff] [0000] ........ => Color index #index, Red #red, Green #green, Blue #blue
00000038: [0006] [ffff] [cccc] [ffff] ........ => Color index #index, Red #red, Green #green, Blue #blue
00000040: [0007] [ffff] [cccc] [cccc] ........ => Color index #index, Red #red, Green #green, Blue #blue
00000048: [0008] [ffff] [cccc] [9999] ........ => Color index #index, Red #red, Green #green, Blue #blue
[ ... ]
000007d8: [00fa] [7777] [7777] [7777] ..wwwwww => Color index #index, Red #red, Green #green, Blue #blue
000007e0: [00fb] [5555] [5555] [5555] ..UUUUUU => Color index #index, Red #red, Green #green, Blue #blue
000007e8: [00fc] [4444] [4444] [4444] ..DDDDDD => Color index #index, Red #red, Green #green, Blue #blue
000007f0: [00fd] [2222] [2222] [2222] .."""""" => Color index #index, Red #red, Green #green, Blue #blue
000007f8: [00fe] [1111] [1111] [1111] ........ => Color index #index, Red #red, Green #green, Blue #blue
00000800: [00ff] [0000] [0000] [0000] ........ => Color index #index, Red #red, Green #green, Blue #blue
That looks pretty straightforward. A u32 0 (probably the minimum color number), a u32 max color (255 in this case), and then each entry is u16[4]: index, r, g, b. (annotate) So we write a little clut decoder:
function load_clut(inc) {
inc.read(7);
let colors = inc.readn(1);
let table = Array(colors);
while (inc.tell() < inc.length()) {
inc.read8();
let c = inc.read8();
table[c] = { r: inc.read16() / 65535 * 255,
g: inc.read16() / 65535 * 255,
b: inc.read16() / 65535 * 255 }
}
return table;
}
And then use the clut in the draw function instead of just making up a greyscale value:
diff a/main.js b/main.js
--- a/main.js
+++ b/main.js
@@ -12,7 +13,7 @@ function erase() {
view.clearRect(0,0, view_el.width, view_el.height);
}
-function draw(data, width, height, bpp, start=0, stride=undefined) {
+function draw(clut, data, width, height, bpp, start=0, stride=undefined) {
if (stride==undefined)
stride = width * bpp;
else
@@ -22,8 +23,7 @@ function draw(data, width, height, bpp, start=0, stride=undefined) {
for (let y=0; y<height; y++) {
for (let x=0; x<width; x++) {
let pix=data.get(start*8 + y * stride + x * bpp, bpp);
- let pix255=pix*255/(2**bpp-1);
- view.fillStyle = `rgb(${pix255},${pix255},${pix255})`;
+ view.fillStyle = `rgb(${clut[pix].r},${clut[pix].g},${clut[pix].b})`;
view.fillRect(x*zoom, y*zoom, zoom, zoom);
}
}
@@ -40,13 +40,15 @@ function main() {
let level_packed = new Bits(level_sprd);
let level = unpack(level_packed);
+ let clut = load_clut(new Bits(Standard_clut));
+
let width, height, bpp, offset;
let go = (event) => {
width = +el.width.value;
height = +el.height.value;
bpp = +el.bpp.value;
offset = +el.offset.value;
- draw(level, width, height, bpp, offset);
+ draw(clut, level, width, height, bpp, offset);
};
Object.values(el).forEach(el => el.oninput = go);
And…
Success again!
Wait, it’s not done??
Now that we’ve gotten “Level” to render, we plug in the snake head sprite in its place:
Uh oh! Why one head? It’s supposed to have a bunch of frames of animation… And why is it so wide?
Time to dive back into the command stream, but let’s just start with the header:
00000000: [0000][0000] .... => Unknown zeros #+b-top, Unknown zeros #+b-left,
00000004: [0018][0018] .... => Height #+b-bottom, Width #+b-right
00000008: [00000250] ...P => File length #+length
[0000000c]: [0000][0113] .... => Offset the length is based from #+offset, Unknown zeros #+d-top, Wait those aren't zeros! #+d-left
00000010: [0018][012b] ...+ => Height (Again!) #+d-bottom, Wait that's not the width! #+d-right
Right off the bat it’s different. The other header had the length/width repeated twice, this one has totally different stuff the 2nd time. Also That 0x250 length doesn’t look quite right: the file is 64K and that’s nowhere close to it. This header must just represent one animation frame and not the whole file (annotate). But what is with those 2nd sets of numbers?
Previously I kind of skimmed over the zeros in the first and fourth u32s since they didn’t really seem to affect anything, but now one of them was a 0x113. And why is the width 0x12b (299 decimal)? I started thinking it may be a stride—an offset between rows somehow. That kind of explained why the sprite with a single frame had the stride equal to the width. But then what was the 0x113 (275 decimal) number? Some sort of vertical stride/interleave number? Neither of those seemed reasonable. We pursued a bunch of leads here, adding and subtracting offsets from all over the file trying to make things line up. And then at one point it suddenly dawned on us: 0x12b –0x113 was 0x18. Then it struck me—that’s not an (x,y) offset plus (width,height) that I was assuming—it’s the old Mac standard way of specifying a rectangle (top, left, bottom, right)! (annotate) Aha, and that explained the zeros in the first u32. Those first 4 u16s are also a rectangle. They must be the bounds of the sprite, and the second rectangle must be the destination in the sprite sheet they’re building (annotate).
Let find out how to find the other sprite frames and maybe it will become clear. Using the 0x250 length (at offset 8 in the header) and adding it to 0xc (I am able to do that addition in my head) we can check what’s past the first sprite:
[00000258]: [00][000000] .... => #line-258, Picture command terminator #+command-null, Zeros #+command-null
[0000025c]: [0000][0000] .... => #line, Bounds rect top #b-top, Bounds rect left #b-left,
[00000260]: [0018][0018] .... => #line, Bounds rect bottom #b-bottom, Bounds rect right #b-right
[00000264]: [0000022c] ..., => #line, Frame length #length
[00000268]: [0000][012c] ..., => Offset the frame length is based from #offset, Destination rect top #d-top, Destination rect left #d-left
[0000026c]: [0018][0144] ...D => #line, Destination rect bottom #d-bottom, Destination rect right #d-right
(The 0x258 line is the null termination command of the first sprite, shown here just for context).
Well… that just looks like another whole header. That seems easy enough. (annotate) But how do we know how big to make our sprite sheet? I guess we could go through every sprite and calculate the max (bottom,left) to know how big we need to make our canvas. But… I don’t really want to do that, it seems annoying. Then I had a thought, “what if I just ignore their ‘destination’ rectangle?”
After all, we just want to be able to grab one and display it, we don’t necessarily need to recreate their sprite sheet verbatim. That also makes it really easy. We’ll pass an extra parameter to our unpack() function (the sprite number) and to a loop over all the pictures until we get to the one we want. That’s super easy because we can just jump to the next one using the length in the header—we don’t need to parse anything in the actual picture.
Here’s just the top half of the new unpack() function (since it’s getting big now and the bottom part didn’t really change):
function unpack(data, want_frame=0) {
data.seek(0);
let frame = 0;
let width,height,out;
while (data.tell() < data.length()) {
console.log("header")
let bounds_top = data.read16()
let bounds_left = data.read16()
let bounds_bottom = data.read16()
let bounds_right = data.read16()
height = bounds_bottom - bounds_top
width = bounds_right - bounds_left
console.log(` bounds rect (${bounds_top},${bounds_left},${bounds_bottom},${bounds_right}) ` +
`(width ${width}, height ${height})`)
let length = data.read32()
let next_frame = data.tell() + length;
console.log(` length ${dec_and_hex(length)} (end:${dec_and_hex(next_frame)})`)
let dest_top = data.read16()
let dest_left = data.read16()
let dest_bottom = data.read16()
let dest_right = data.read16()
console.log(` dest rect (${dest_top},${dest_left},${dest_bottom},${dest_right})`)
if (frame != want_frame) {
data.seek(next_frame);
frame++;
continue;
}
out = new Bits(Array(width * height).fill(0))
[ ... ]
I also decided to add another text entry for setting which frame to look at (just like all the others you can PgUp and PgDown to increment or decrement), and a popup menu to set which sprite-set to display:
\o/
Now I think we’re done—we’ve successfully figured out every byte of the file format and can unwrap any sprite and display it on the screen with the correct colors.